ViT一种Google开源的大规模CNN图像识别模型
作为朝这个方向迈出的第一步,我们介绍了(ViT),这是一种视觉模型,该模型尽可能地基于最初为基于文本的任务而设计的Transformer体系结构。ViT将输入图像表示为图像块序列,类似于在将”变形金刚”应用于文本时使用的单词嵌入序列,并直接预测图像的类标签。当在足够的数据上进行训练时,ViT表现出卓越的性能,其性能比同类最新的CNN少四倍。为了促进在这一领域的更多研究,我们将代码和模型都开源了。
继续阅读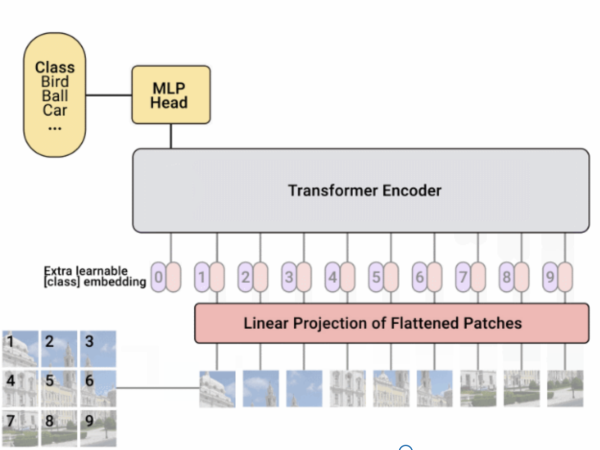
作为朝这个方向迈出的第一步,我们介绍了(ViT),这是一种视觉模型,该模型尽可能地基于最初为基于文本的任务而设计的Transformer体系结构。ViT将输入图像表示为图像块序列,类似于在将”变形金刚”应用于文本时使用的单词嵌入序列,并直接预测图像的类标签。当在足够的数据上进行训练时,ViT表现出卓越的性能,其性能比同类最新的CNN少四倍。为了促进在这一领域的更多研究,我们将代码和模型都开源了。
继续阅读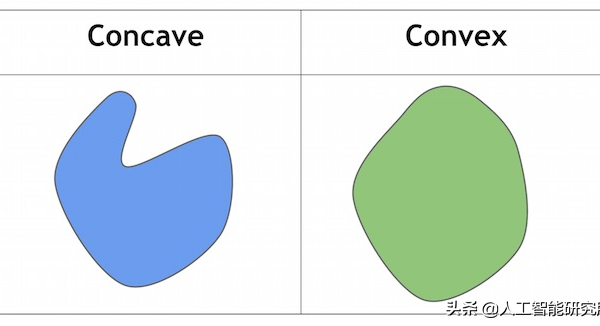
blob是图像中一组共享的区域,它们具有一些共同的属性(例如灰度值,形状,尺寸等)blob检测的目的是识别并标记一些特定区域,blob检测在自动化工业领域比较常见。OpenCV提供了一种方便的方法来检测blob并根据不同的特征对其进行过滤。那就是SimpleBlobDetector检测算法
继续阅读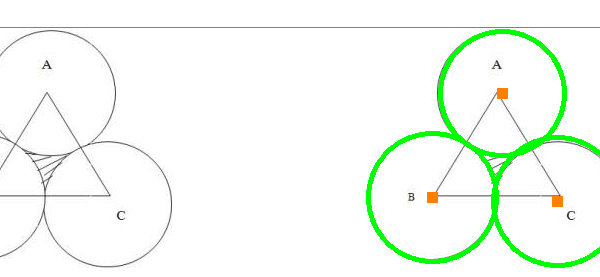
今天我们介绍一个opencv 函数cv2.HoughCircles(),此函数主要用于检测图像中的圆形,我们知道3点可以画一个圆,学习CAD的同学肯定知道,opencv使用霍夫梯度的方法进行圆的检测
继续阅读

基于深度学习的对象检测时,我们主要分享以下三种主要的对象检测方法:
Faster R-CNN(后期会来学习分享)
你只看一次(YOLO,最新版本YOLO3,后期我们会分享)
单发探测器(SSD,本节介绍,若你的电脑配置比较低,此方法比较适合)
继续阅读