大数据开发神器——Scrapy 框架(读懂Spider流程图)
上期我们简单讲述了Scrapy 框架的基本构成,本期文章主要以一种简单的对话形式介绍一下Scrapy流程图
Scrapy框架
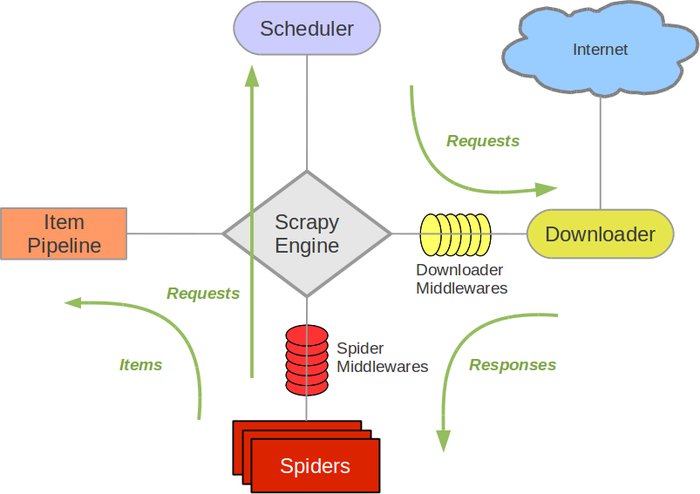
Scrapy框架流程图
从Scrapy的流程图,我们知道Scrapy Engine(引擎)作为Scrapy的大脑,主要负责spider的协调工作,当spider运行时:
Scrapy Engine(引擎):spider,你好,你好爬取那个网站? Spider(爬虫): 你好,引擎,我要爬取HTTP:\\www.XXXXXX.COM Scrapy Engine(引擎): 那你把你需要爬取的第一个URL地址给我吧 Spider(爬虫): 好的,这个是第一个URL地址:www.xxxx.com Scrapy Engine(引擎): hello Scheduler(调度器),spider提供了一个request(请求),你 协助排队处理一下 Scheduler(调度器): 好的,等待处理,你稍等一下 Scrapy Engine(引擎):hello Scheduler(调度器),request(请求)处理好的给我一下 Scheduler(调度器): 已经OK,这是处理好的request,给你 Scrapy Engine(引擎):hello Downloader(下载器),你按照Downloader Middlewares(下载中间件,主要设置下载的一些参数)的设置,协助下载一下这个 request Downloader(下载器):OK,等待下载,已经完成,给你下载好的资料(若下载失败,Engine会告诉Scheduler,记录失败的位置,等待后期重新下载) Scrapy Engine(引擎):hello Spider Middlewares(Spider中间件),这是下载器下载的资料,你按照设置的参数处理一下 Scrapy Engine(引擎):hello spider 这是下载且处理好的资料,你再处理一下 Spider(爬虫):hello engine,这是我获取到的Item, 还有需要跟进的URL ,你再跟进一下 Scrapy Engine(引擎):hello Item Pipeline(主要负责item的数据保存), 这是spider获取的Item,你处理一下,hello Scheduler(调度器),这是spider要求需要跟进的URL,你处理一下。然后回到第五步,开始循环执行,直到所有的URL处理完毕
当所有的URL执行完成后,engine会通知Scheduler里面是否有以前下载失败的URL,若有程序会重新下载,直到结束
安装Scrapy
若你习惯了pychram,在安装scrapy前,你需要安装pywin32、pyOpenSSL、Twisted、lxml 、 zope.interface等第三方依赖库,但是不建议使用pycharm来安装scrapy,推荐使用anaconda(参考往期的文章)安装,避免遗漏第三方依赖库。
下期预告
通过以上的学习,我们了解了scrapy的基本组件与整个spider的流程,下期我们新建一个spider,爬取第一个网页
