无人自动驾驶技术之使用OpenCV进行相机校准
照相机与摄像头,是机器人,人工智能,计算机视觉,工业自动化甚至娱乐行业等多个领域的组成部分。在我们使用此设备时,不仅要了解照相原理外,需要使用特殊的技术对摄像头进行相机校准,特别在自动化驾驶上,需要实时的对照相机进行校准操作
继续阅读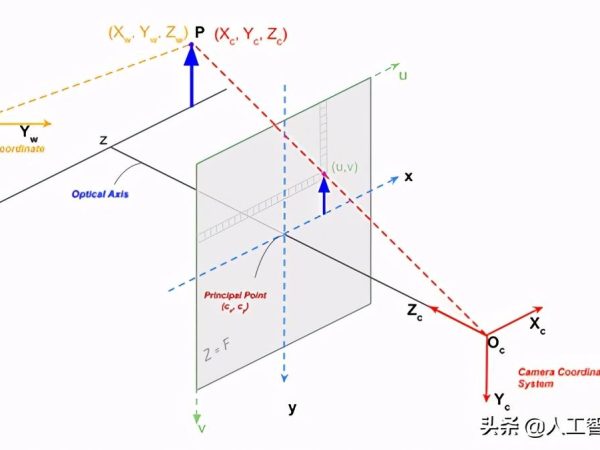
照相机与摄像头,是机器人,人工智能,计算机视觉,工业自动化甚至娱乐行业等多个领域的组成部分。在我们使用此设备时,不仅要了解照相原理外,需要使用特殊的技术对摄像头进行相机校准,特别在自动化驾驶上,需要实时的对照相机进行校准操作
继续阅读
上期文章我们分享了基于OpenCV的超分辨率的代码实现,哪里主要使用到了EDSR、ESPCN、FSRCNN、LapSRN等模型,虽然使用OpenCV能够实现超分辨率,但是图片的清晰图并没有增加,当有一张稍微模糊的图片时,增加分辨率的同时,我们也更希望提高图片的清晰图,如上图的图片,本期文章,我们介绍一下USRNet模型结构
继续阅读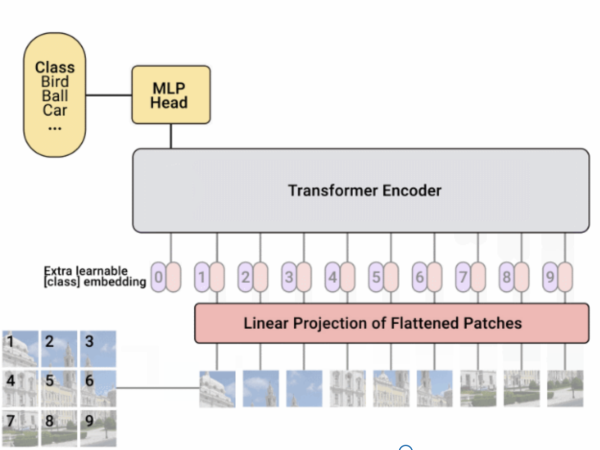
作为朝这个方向迈出的第一步,我们介绍了(ViT),这是一种视觉模型,该模型尽可能地基于最初为基于文本的任务而设计的Transformer体系结构。ViT将输入图像表示为图像块序列,类似于在将”变形金刚”应用于文本时使用的单词嵌入序列,并直接预测图像的类标签。当在足够的数据上进行训练时,ViT表现出卓越的性能,其性能比同类最新的CNN少四倍。为了促进在这一领域的更多研究,我们将代码和模型都开源了。
继续阅读
什么是视频与图片的超分辨率,总结一下便是给一张分辨率比较低的图片,进行超分辨率的处理后,生成比较清晰的高分辨率的图片,上图图片完美解释了超分辨率的过程,由于不同的算法不同,处理的结果也不相同,本期我们介绍一下如何进行图片的超分辨率的处理。
继续阅读
前几期的文章,我们分享了人脸468点检测与人手28点检测的代码实现过程,本期我们进行人体姿态的检测与评估
继续阅读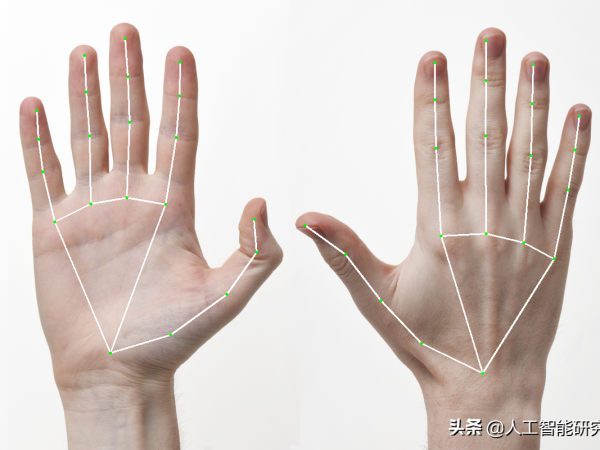
MediaPipe Hands是一种高保真手和手指跟踪解决方案。它采用机器学习(ML)来从一个帧中推断出手的21个3D界标。
继续阅读
上期文章,我们分享了,MediaPipe Face Mesh是一种脸部几何解决方案,即使在移动设备上,也可以实时估计468个3D脸部界标(dlib才能检测出68点)。它采用机器学习(ML)来推断3D表面几何形状,只需要单个摄像机输入,而无需专用的深度传感器。该解决方案利用轻量级的模型架构以及整个管线中的GPU加速,可提供对实时体验至关重要的实时性能。本期我们介绍一下代码如何实现
继续阅读
MediaPipe Face Mesh是一种脸部几何解决方案,即使在移动设备上,也可以实时估计468个3D脸部界标。它采用机器学习(ML)来推断3D表面几何形状,只需要单个摄像机输入,而无需专用的深度传感器。该解决方案利用轻量级的模型架构以及整个管线中的GPU加速,可提供对实时体验至关重要的实时性能。
继续阅读
仅通过在照片上训练模型,机器学习(ML)的最新技术就已经在许多计算机视觉任务中实现了卓越的准确性。基于这些成功和不断发展的3D对象理解,在增强现实,机器人技术,自主性和图像检索等广泛应用方面具有巨大潜力。例如,今年早些时候,Google发布了MediaPipe Objectron(一套针对移动设备设计的实时3D对象检测模型),它们在完全注释的真实3D数据集上进行了训练,可以预测对象的3D边界框。
继续阅读
MediaPipe 是一款由 Google Research 开发并开源的多媒体机器学习模型应用框架。在谷歌,一系列重要产品,如 、Google Lens、ARCore、Google Home 以及 ,都已深度整合了 MediaPipe。
继续阅读