大数据开发神器——Scrapy Spider框架
说道Python,估计很多同学跟我一样都是从学习Python的爬虫开始的。当然你可以使用lxml、BeautifulSoup、Request等第三方库来编写自己的爬虫。但是当需要爬取海量数据,特别是大数据的实际应用中,若自己编写爬虫,是一件特别困难的事情。还好Python提供了类似Scrapy等类似的爬虫框架(人生苦短,我用Python)
Scrapy框架介绍
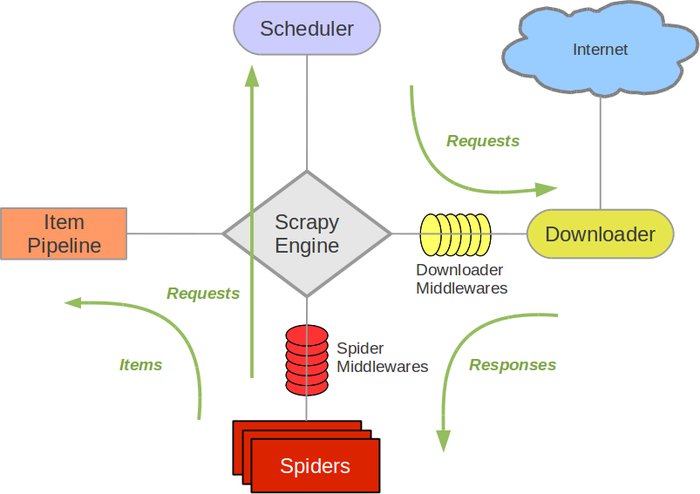
Scrapy Spider 框架图
Scrapy | A Fast and Powerful Scraping and Web Crawling Framework
Scrapy框架主要包括:
Scrapy Engine(引擎)、Scheduler(调度器)、Downloader(下载器)、Spiders(爬虫)、Item Pipeline、Downloader Middlewares(下载中间件)、Spider Middlewares(Spider中间件)
1、Scrapy Engine(引擎):负责Spiders、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等等!(爬虫的大脑)
2、Scheduler(调度器): 负责接受引擎发送过来的requests请求,并按照一定的方式进行整理排列,入队、并等待Scrapy Engine(引擎)来请求时,交给引擎
3、Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spiders来处理
4、Spiders(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
5、Item Pipeline:负责处理Spiders中获取到的Item,并进行处理,比如去重,持久化存储(存数据库,写入文件,总之就是保存数据用的)
6、Downloader Middlewares(下载中间件):一个可以自定义扩展下载功能的组件
7、Spider Middlewares(Spider中间件):一个可以自定义扩展和操作引擎,负责Spiders中间‘通信‘的功能组件(比如进入Spiders的Responses和从Spiders出去的Requests)
下期预告
本期简单介绍一下scrapy的几个基本知识,下期讲述一下scrapy的简单流程图以及安装事宜
