ViT一种Google开源的大规模CNN图像识别模型
虽然(细胞神经网络)已经在计算机视觉中使用自20世纪80年代,他们没有走在了前列直到2012年,当AlexNet大幅度超过了国家的最先进的现代图像识别方法的性能。有两个因素帮助实现了这一突破:(i)像ImageNet这样的训练集的可用性,以及(ii)使用商品化的GPU硬件,后者为训练提供了更多的计算量。因此,自2012年以来,CNN已成为视觉任务的首选模型。
使用CNN的好处在于,它们无需手工设计的视觉功能,而是学习直接从数据”端到端”执行任务。但是,尽管CNN避免了手工提取特征,但该体系结构本身是专门为图像设计的,可能需要进行计算。展望下一代可扩展视觉模型,人们可能会问这种特定区域的设计是否必要,或者是否可以成功地利用更多与域无关的和计算效率高的体系结构来获得最新的结果。
作为朝这个方向迈出的第一步,我们介绍了(ViT),这是一种视觉模型,该模型尽可能地基于最初为基于文本的任务而设计的Transformer体系结构。ViT将输入图像表示为图像块序列,类似于在将”变形金刚”应用于文本时使用的单词嵌入序列,并直接预测图像的类标签。当在足够的数据上进行训练时,ViT表现出卓越的性能,其性能比同类最新的CNN少四倍。为了促进在这一领域的更多研究,我们将代码和模型都开源了。
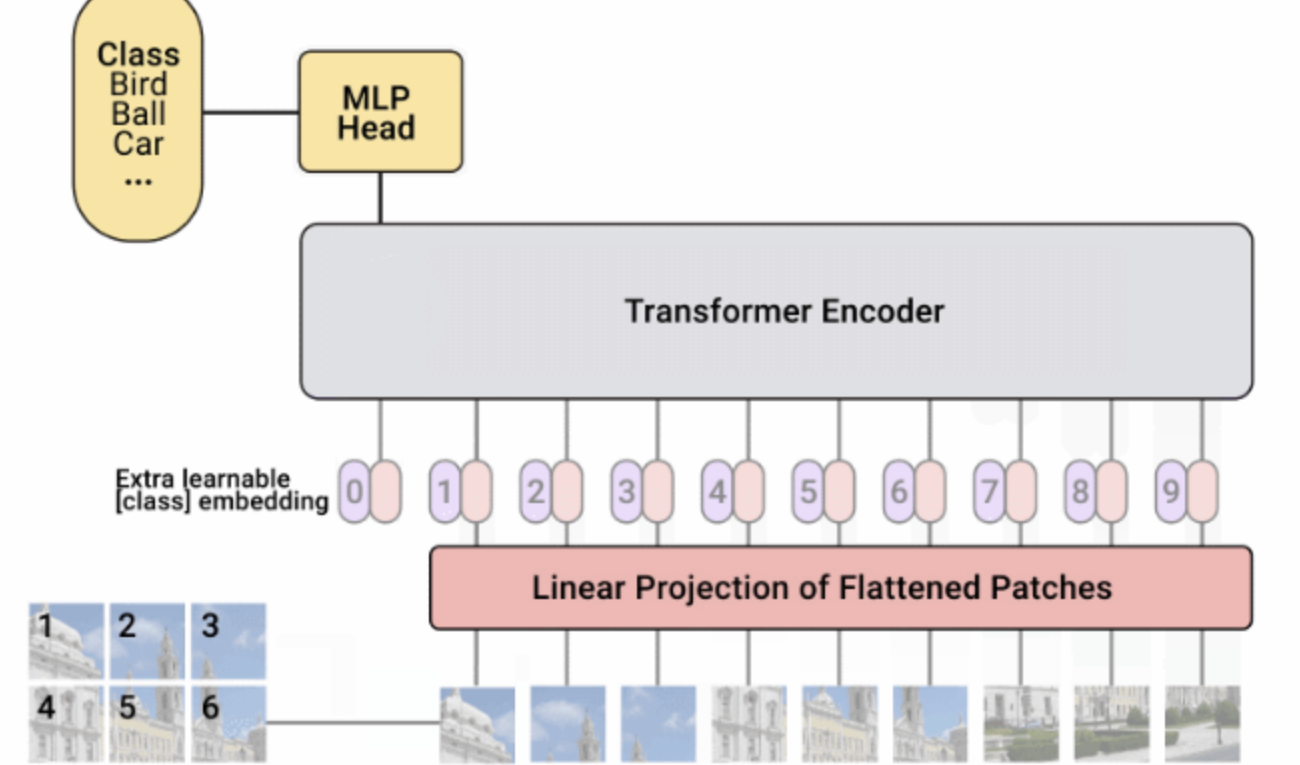
视觉变形金刚原始文本变形金刚以单词序列作为输入,然后将其用于,或其他NLP任务。对于ViT,我们对Transformer设计进行了尽可能少的修改,以使其直接在图像上运行,而不是在文字上运行,并观察模型可以自己学习多少图像结构。
ViT将图像分成正方形补丁的网格。通过连接一个贴片中所有像素的通道,然后将其线性投影到所需的输入尺寸,可以将每个贴片展平为单个矢量。由于变形金刚与输入元素的结构无关,因此我们在每个补丁中添加了可学习的位置嵌入,从而使模型可以了解图像的结构。ViT先验地不知道图像中补丁的相对位置,甚至不知道图像具有2D结构-它必须从训练数据中学习此类相关信息,并将结构信息编码在位置嵌入中。
我们首先在ImageNet上对ViT进行了训练,在该网络上,ViT的top-1准确性达到了77.9%的最高分数。虽然这是第一次尝试的不错的做法,但它与最新技术水平相去甚远-在ImageNet上训练的最好的CNN(无额外数据)达到85.8%。尽管采取了缓解策略(例如正则化),但由于ViT缺乏对图像的内在知识,ViT仍然适合ImageNet任务。
为了研究数据集大小对模型性能的影响,我们在(14M图像,21k类)和JFT(300M图像,18k类)上训练了ViT ,并将结果与最新的CNN进行了比较,大转移(BiT),在相同的数据集上进行训练。如先前观察到的,当在ImageNet上训练(1M图像)时,ViT的性能明显比CNN等效(BiT)差。但是,在ImageNet-21k(1400万张图像)上,性能是可比的;在JFT(3亿张图像)上,ViT现在比BiT更好。
最后,我们研究了训练模型所涉及的计算量的影响。为此,我们在JFT上训练了几种不同的ViT模型和CNN。这些模型涵盖了各种模型大小和训练持续时间。结果,他们需要不同数量的计算来进行训练。我们观察到,对于给定的计算量,ViT比等效的CNN产生更好的性能。
高性能大规模图像识别我们的数据表明,(1)经过充分训练的ViT可以很好地执行,并且(2)ViT在较小和较大的计算规模下均具有出色的性能/计算折衷。因此,要查看性能提升是否还能延续到更大的规模,我们训练了一个600M参数的ViT模型。
这种大型的ViT模型在多个流行的基准上均具有最先进的性能,包括ImageNet上的top-1精度为88.55%,CIFAR-10上为99.50%。ViT在清理版本的ImageNet评估集” ImageNet-Real”上也表现出色,达到了90.72%的top-1准确性。最后,即使没有训练数据点,ViT仍可以很好地完成各种任务。例如,在(每个任务有1000个数据点的19个任务)上,ViT达到77.63%,大大领先于单模型技术(SOTA)(76.3%),甚至与SOTA达到多个模型的合计(77.6%)。最重要的是,与以前的SOTA CNN相比,使用较少的计算资源即可获得这些结果,例如,比预训练的BiT模型少4倍。
可视化为了对模型学到的东西有一些直觉,我们将其内部工作可视化。首先,我们看一下位置嵌入-模型学习的参数,以编码补丁的相对位置-并发现ViT能够重现直观的图像结构。每个位置嵌入与同一行和同一列中的其他位置最相似,这表明该模型已恢复原始图像的网格结构。其次,我们检查每个变压器块的一个元件与另一个元件之间的平均空间距离。在较高层(深度为10-20),仅使用全局特征(即,较大的注意距离),但较低层(深度为0-5)捕获了全局和局部特征,如平均注意范围较大距离。相比之下,CNN的较低层中仅存在局部特征。这些实验表明,ViT可以学习硬编码到CNN中的特征(例如对网格结构的了解),但也可以自由地学习更多通用的模式,例如较低层的局部和全局特征的混合,这有助于泛化。
总结尽管CNN彻底改变了计算机视觉,但我们的结果表明,为成像任务量身定制的模型可能不是必需的,甚至不是最佳的。随着数据集规模的不断扩大,以及无监督和半监督方法的不断发展,开发在这些数据集上进行更有效训练的新视觉架构变得越来越重要。我们相信,ViT是迈向通用,可扩展架构的第一步,该架构可以解决许多视觉任务,甚至来自多个领域的任务,并为未来的发展感到兴奋。
https://m.toutiao.com/is/iLjn9d26/ 人工智能研究所: 视频动画详解Transformer模型–Attention is all you need.


