谷歌百度以图搜图如何实现?教你打造属于自己的相似图片搜索引擎
相似图片
前情回顾:
前期文章,我们分享了图片的3D颜色直方图,利用颜色直方图是反映图片的像素的分布状态,当然不同的图片,其颜色直方图肯定有所不同,利用不同图片的颜色直方图的对比值,便可以很容易找到2张相似的图片。
图片的3D颜色直方图:
既然要使用图片的颜色直方图来进行相似图片的对比,首先需要对图片进行直方图的数据收集与保持
import pickle
import cv2
import os
class RGBHistogram:
def __init__(self, bins):
self.bins = bins
def describe(self, image):
hist = cv2.calcHist([image], [0, 1, 2],None, self.bins, [0, 256, 0, 256, 0, 256])
hist = cv2.normalize(hist,hist)
return hist.flatten()代码截图
首先我们建立一个计算图片 RGB空间的3D颜色直方图函数,利用此函数来进行图片直方图的计算工作
我们依然使用cv2.calcHist函数来进行图片直方图的计算,关于此函数的具体参数定义,可以参考往期文章,这里我们一般搜索的图片为彩色图片,所以计算图片的RGB空间直方图
然后使用cv2.normalize opencv 图片归一化函数(归一化数据。该函数分为范围归一化与数据值归一化),通俗地讲就是将矩阵的值通过某种方式变到某一个区间内,这样可以有效的节约计算机空间来计算
Cv.normalize(InputArry src,InputOutputArray dst,double alpha=1,
double beta=0,int norm_type=NORM_L2,int dtype=-1,InputArray mark=noArry())- · src 输入数组;
- · dst 输出数组,数组的大小和原数组一致;
- · alpha 1,用来规范值,2.规范范围,并且是下限;
- · beta 只用来规范范围并且是上限;//为0时则为值归一化,否则为范围归一化
- · norm_type 归一化选择的数学公式类型;
- · dtype 当为负,输出在大小深度通道数都等于输入,当为正,输出只在深度与输入不同,不同的地方由dtype决定;
- · mark 掩码。选择感兴趣区域,选定后只能对该区域进行操作。
然后返回flatten数组形式的3D图片直方图
收集图片直方图数据:
建立好了图片直方图函数,便可以收集我们的图片直方图的数据,这里跟我们首先需要神经网络类似,需要有前期的”预训练模型”
index = {}
desc = RGBHistogram([8, 8, 8])
list_images = []
for root, dirs, files in os.walk("images"):
for file in files:
list_images.append(os.path.join(root, file))
for imagePath in list_images:
k = imagePath[imagePath.rfind("/") + 1:]
image = cv2.imread(imagePath)
features = desc.describe(image)
index[k] = features
with open("index.cpickle", "wb") as f:
f.write(pickle.dumps(index))index{} 字典用来保存图片的路径与图片直方图数据
for root, dirs, files in os.walk,首先使用os.walk 函数遍历整个图片的文件夹来获取图片的相对路径地址
我们按照imagePath[imagePath.rfind(“/”) + 1:]图片的路径作为key , 图片的features = desc.describe(image)直方图数据作为value组成一个index字典用来保存图片的数据
待获取了图片的字典数据后,我们使用f.write(pickle.dumps(index))
保存图片的直方图数据,以便后期进行搜索使用,当然这部分数据可以保存到自己的服务器上,当用户搜索相识图片时,前端获取用户的图片数据,服务器进行相识图片检索,然后返回前端检索到的图片数据进行图片的展示。
代码截图
以上我们搜集了图片的直方图数据,并保存了数据,这点跟我们前期讲解的神经网络的预训练模型类似,下一步当然是进行”神经网络的预测”进行图片的检测
相关图片的搜索:
想要进行图片的相识图片搜索工作,首先保证前面几个步骤已经完成,且保存了自己的数据,接下来当然是接受用户的输入图片,进行图片的相识性搜索
import numpy as np
import os
import pickle
import cv2
class RGBHistogram:
def __init__(self, bins):
self.bins = bins
def describe(self, image):
hist = cv2.calcHist([image], [0, 1, 2],
None, self.bins, [0, 256, 0, 256, 0, 256])
hist = cv2.normalize(hist,hist)
return hist.flatten()首先我们建立图片直方图的函数,这里这个函数主要是把用户传递过来的图片进行图片直方图的操作,函数的具体含义参考以上文章内部
代码截图
然后我们新建一个搜索函数,主要处理输入直方图与数据库直方图的对比
class Searcher:
def __init__(self, index):
self.index = index
def search(self, queryFeatures):
results = {}
for (k, features) in self.index.items():
d = self.chi2_distance(features, queryFeatures)
results[k] = d
results = sorted([(v, k) for (k, v) in results.items()])
return results
def chi2_distance(self, histA, histB, eps = 1e-10):
d = 0.5 * np.sum([((a - b) ** 2) / (a + b + eps)
for (a, b) in zip(histA, histB)])
return d首先我们加载index数据库,这里保存了图片的直方图数据
然后遍历所有index的数据for (k, features) in self.index.items():计算每个数据库中的图片直方图与输入图片直方图的卡方距离
卡方距离
卡方距离越小,说明2张图片越相似
利用sorted 函数sorted([(v, k) for (k, v) in results.items()])
对图片卡方距离进行排序,以便最小的距离值排列在最前面
代码截图
初始化数据
queryImage = cv2.imread("queries/11.png")
cv2.imshow("Query", queryImage)
desc = RGBHistogram([8, 8, 8])
queryFeatures = desc.describe(queryImage)
index = pickle.loads(open("index.cpickle", "rb").read())
searcher = Searcher(index)
results = searcher.search(queryFeatures)
montageA = np.zeros((166 * 3, 400, 3), dtype="uint8")
montageB = np.zeros((166 * 3, 400, 3), dtype="uint8")首先接受用户传递的图片
desc = RGBHistogram([8, 8, 8])
queryFeatures = desc.describe(queryImage)
使用以上函数计算用户图片的颜色直方图
index = pickle.loads(open(“index.cpickle”, “rb”).read())
searcher = Searcher(index)
初始化颜色直方图搜索引擎数据,主要是打开服务器上的图片直方图数据进行图片的搜索
results = searcher.search(queryFeatures)
进行图片的相似性检索
tageA = np.zeros((166 * 3, 400, 3), dtype=”uint8″)
tageB = np.zeros((166 * 3, 400, 3), dtype=”uint8″)
初始化2个标签,用来展示我们搜索到的相似图片,这里我们方便查看设置了6张图片的展示
每个图片resize 到400*166
当然你完全可以只展示一张最相似的图片
代码截图
我们检索了所有数据库中的图片,结果已经存放在results数组中,由于我们sorted了数组,所以最小值的前六个数组当然在数组最前面,我们只需要提取前6个数据即可
for j in range(0, 6):
(score, imageName) = results[j]
path = os.path.join(imageName)
result = cv2.imread(path)
if j < 3:
tageA[j * 166:(j + 1) * 166, :] = result
else:
tageB[(j - 3) * 166:((j - 3) + 1) * 166, :] = result
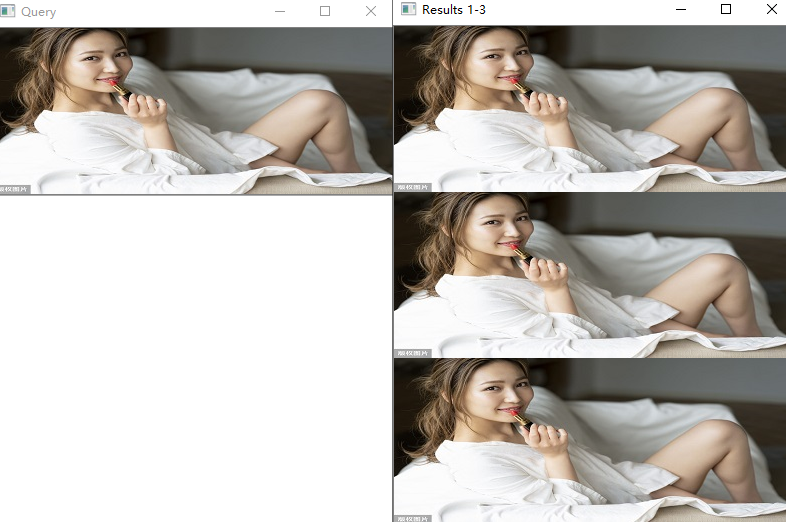
cv2.imshow("Results 1-3 ", tageA)
cv2.imshow("Results 4-6 ", tageB)
cv2.waitKey(0) 遍历前6个数据,获取图片保存的路径地址与每个图片相似度的置信度
把前3个图片数据保存到tageA中,后3个图片数据保存到tageB中,最后便可以成功展示我们检索到的6张相似图片
代码截图
这里程序成功的找到了相似图片,小编这里复制了3张图片,程序能够完美找到图片
相似图片
