人工智能TensorFlow(十一)过拟合(Overfitting)与dropout
过拟合(Overfitting)
overfittingt是这样一种现象:一个假设在训练数据上能够获得比其他假设更好的拟合,但是在训练数据外的数据集上却不能很好的拟合数据。此时我们就叫这个假设出现了overfitting的现象。出现这种现象的主要原因是训练数据中存在噪音或者训练数据太少.
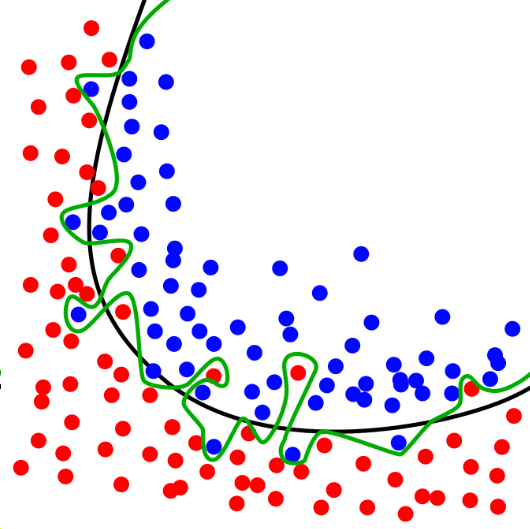
如上图:图中黑色曲线是正常模型,绿色曲线就是overfitting模型。尽管绿色曲线很精确的区分了所有的训练数据,但是并没有描述数据的整体特征,对新测试数据的适应性较差,且训练模型太复杂,后期的训练数据会很庞大。
上图3中的训练,就是TensorFlow过度训练,完全覆盖了所有数据,但是使用TensorFlow来训练模型,我们是想使用简单的模型来训练复杂的实际应用。
出现overfiting现象的主要原因是训练数据中存在噪音或者训练数据太少,那么主要的解决方式就是:
1、增加数据量
2、通过Regularization减少overfitting
3、通过dropout
正则化(regularization)
最常见的一种Regularization:L1,L2 Regularization
在cross-entropy的基础上增加一项:权重之和(对于神经网络里面所有权重W相加)
regularization的cost偏向神经网络学习比较小的权重W,Regularized网络更鼓励小的权重, 小的权重的情况下, x一些随机的变化不会对神经网络的模型造成太大影响, 所以更小可能受到数据局部噪音的影响.
Dropout
Dropout的目的也是用来减少overfitting(过拟合)。而和L1,L2Regularization不同的是,Dropout不是针对cost函数,而是改变神经网络本身的结构。
假设有一个神经网络:
按照之前的方法,根据输入X,先正向更新神经网络,得到输出值,然后反向根据backpropagation算法来更新权重和偏向。而Dropout不同的是,
1)在开始,随机删除掉隐藏层一半的神经元,如图,虚线部分为开始时随机删除的神经元:
2)然后,在删除后的剩下一半的神经元上正向和反向更新权重和偏差;
3)再恢复之前删除的神经元,再重新随机删除一半的神经元,进行正向和反向更新w和b;
4)重复上述过程。
最后,学习出来的神经网络中的每个神经元都是在只有一半的神经元的基础上学习的,因为更新次数减半,那么学习的权重会偏大,所以当所有神经元被恢复后,把得到的隐藏层的权重减半。对于同一组训练数据,利用不同的神经网络训练之后,求其输出的平均值可以减少overfitting,Dropout就是利用这个原理,每次丢掉一半的一隐藏层神经元,相当于在不同的神经网络上进行训练,这样就减少了神经元之间的依赖性,即每个神经元不能依赖于某几个其他的神经元(指层与层之间相连接的神经元)
下期分享:
下期我们分享一下,TensorFlow如何使用dropout来完成overfiting的问题(代码)
谢谢大家的点赞与转发,关于分享的文章,大家有任何问题,可以在评论区一起探讨学习!!!
