大数据挖掘神器——scrapy spider爬虫框架(selectors 选择器)
通过上期的简单介绍,我们已经可以新建一个简单的spider,但是细心的网友发现,我们在解析HTML网页的时候是:
tds = BeautifulSoup(response.text, 'lxml').find_all('tr', bgcolor='#FFFFFF')#解析网页
我们使用到了BeautifulSoup:
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式,但是缺点慢。上期网友反馈使用其它解析,本期简单介绍一下scrapy的自带选择器(selectors)
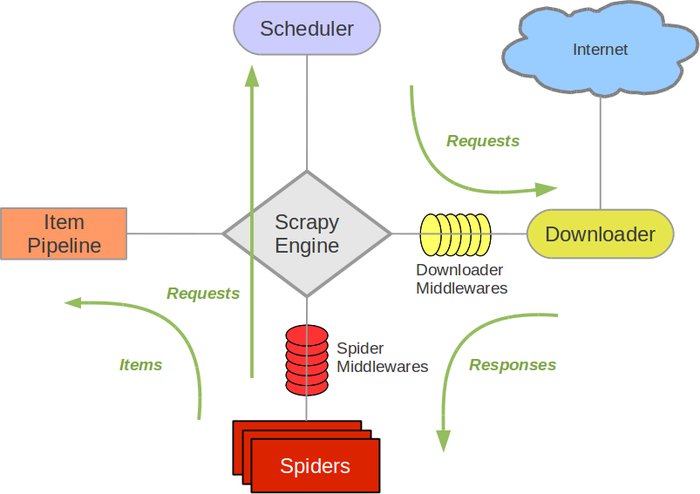
spider 流程图
选择器(Selectors)
当抓取网页时,我们主要的工作是从HTML源码中提取数据。当我们编写spider时,可以使用如下解析器来解析HTML网页数据:
- BeautifulSoup 它基于HTML代码的结构来构造一个Python对象, 缺点:慢。
- lxml 是一个基于 ElementTree (不是Python标准库的一部分)的python化的XML解析库
- scrapy自带解析器(selector),称之为选择器
Scrapy 选择器(seletors),通过特定的 XPath 或者 CSS 表达式来解析HTML文件中的某个部分。
XPath 是一门用来在XML文件中选择节点的语言,也可以用在HTML上。 CSS 是将HTML文档样式化的语言,与特定的HTML元素的样式相关连。 Scrapy选择器构建于 lxml 库之上,速度比BeautifulSoup快,比lxml简洁
我们通过修改上期的代码,正式了解一下XPath
import scrapy import os from scrapy.http import Request from myproject.items import PowersItem class PowersSpider(scrapy.Spider): #爬虫的名字 name = "powers" #允许爬取的域名 allowed_domains = ["23us.so"] #spider的第一个URL start_urls = ['http://www.23us.so/full.html']
使用response.xpath来解析HTML
#这里必须使用parse定义函数,因为scrapy设置的第一个调度函数
def parse(self, response):
#response.xpath解析
tds = response.xpath("//tr[@bgcolor='#FFFFFF']/td[1]/a/text()")
item = PowersItem() # item初始化
for td in tds:
novelname = td.extract() # 获取小说名字
item['novelname'] = novelname # 获取到Items
print(item)
pass
>>>
Xpath选取节点
Xpath使用路径表达式在XML文档中选取节点。节点是通过沿着路径来选取的,通过路径可以找到我们想要的节点或者节点范围。
Xpath节点
Xpath谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
Xpath谓语(Predicates)
Xpath通配符
XPath 通配符可用来选取未知的 XML 元素,通配指定节点。
Xpath通配符
以上列取了Xpath的基本语法结构,关于Xpath的语法详细学习,大家可以到如下地址学习:w3school.com.cn/xpath/
下期预告
OK,我们后期会按照XPath与BeautifulSoup两条路线代码,来接着我们的爬虫工程。
谢谢大家的观看点赞与转发,关于分享的文章,大家有任何问题,可以在评论区一起探讨学习!!!
