大数据开发神器——scrapy spider框架(代码入门篇)
通过以上的分享,我们了解了scrapy框架的流程图以及基本的安装,那么接下来,我们新建一个工程来走入scrapy spider的世界
scrapy spide新建工程
首先打开我们的pycharm IDE软件,在新建工程前,请确保已经安装好scrapy框架,你可以输入下面代码确保scrapy的正常安装:
cmd终端下输入 >>> scrapy -h
scrapy框架确认
创建项目:cmd 进入项目文件夹,输入如下代码
scrapy startproject myproject #myproject是项目名字,你可以自己更改
Scrapy默认是不能在IDE中运行的,我们需要在根目录中新建一个py文件:entrypoint.py,输入如下代码:
from scrapy.cmdline import execute execute(['scrapy', 'crawl', 'powers']) #第三个参数是你自己设置的爬虫的名字
entrypoint.py启动爬虫
通过以上的设置,我们新建了一个scrapy框架的工程,整个文件目录如下:
scrapy项目目录
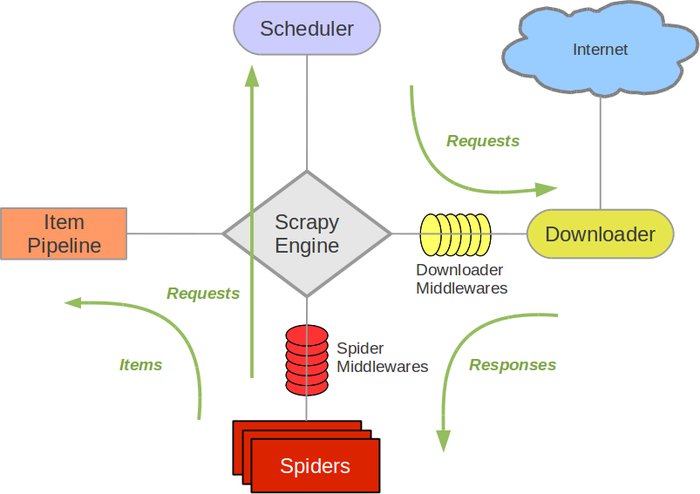
OK,整个工程的准备工作已经完毕,我们需要按照scrapy的流程图,构建我们的爬虫
scrapy流程图
scrapy新建spider
首先,在spider爬虫文件夹下,新建一个py文件powers415.py
第二: 设置spider
打开settings,找到如下代码,在我们前期调试阶段,可以先取消注释
HTTPCACHE_ENABLED = True HTTPCACHE_EXPIRATION_SECS = 0 HTTPCACHE_DIR = 'httpcache' HTTPCACHE_IGNORE_HTTP_CODES = [] HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
这几行注释的作用是Scrapy会缓存你有的Requests!当你再次请求时,如果存在缓存文档则返回缓存文档,而不是去网站请求,这样既加快了本地调试速度,也减轻了 网站的压力
第三:定义Items
根据我们需要爬取的需要,定义我们需要的Items,我们以爬取
https://www.23us.so/full.html此URL为例(一个小说网站),打开此网站,我们可以看到上面有小说的名字,作者,字数,状态等,本次就先爬虫这一个界面的所有小说的名字为例
打开Items 输入如下:
import scrapy class PowersItem(scrapy.Item): novelname = scrapy.Field()#小说名字 pass
以上就是scrapy的基本设置(后续会添加其他的设置,我们后续讨论)
第四:编写spider
打开我们先前建立的py爬虫powers415.py
import scrapy
from bs4 import BeautifulSoup #(解析request来的网页)
from scrapy.http import Request #(request请求)
from myproject.items import PowersItem
#以上是插入scrapy以及其他使用到的第三方库
###########
class PowersSpider(scrapy.Spider):
name = "powers" #爬虫的名字,必须添加爬虫的名字,这个很重要
first_url='http://www.23us.so/full.html' #定义第一个URL
def start_requests(self):
yield Request(self.first_url,self.parse)#返回调度器处理好的request
#spider处理获取的数据,得到Items
def parse(self, response): #必须有parse函数
tds = BeautifulSoup(response.text, 'lxml').find_all('tr', bgcolor='#FFFFFF')#解析
item = PowersItem() #item初始化
for td in tds:
novelname = td.find('a').get_text()#获取小说名字
item['novelname'] =novelname #获取到Items
print(item)
pass
>>>
爬取的数据
下期预告:
OK,到此我们的第一个简单爬虫就介绍完了,下期我们在本次的基础上面,爬取更多的数据
