使用Python代码制作贪吃蛇小游戏,你也可以打造自己的AI
上期视频,我们分享了一个AI来玩贪吃蛇的视频,本期我们讲解一下其基础代码,利用本代码自己也可以写游戏了。
继续阅读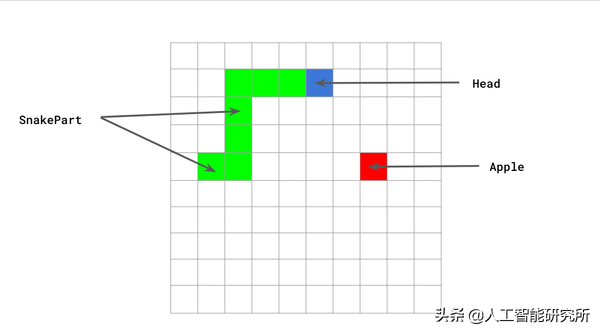
上期视频,我们分享了一个AI来玩贪吃蛇的视频,本期我们讲解一下其基础代码,利用本代码自己也可以写游戏了。
继续阅读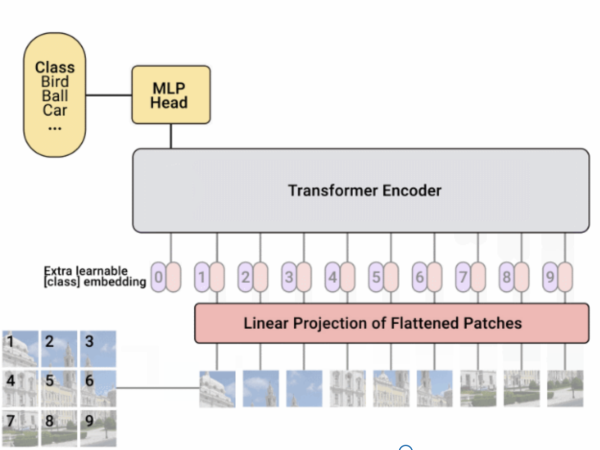
作为朝这个方向迈出的第一步,我们介绍了(ViT),这是一种视觉模型,该模型尽可能地基于最初为基于文本的任务而设计的Transformer体系结构。ViT将输入图像表示为图像块序列,类似于在将”变形金刚”应用于文本时使用的单词嵌入序列,并直接预测图像的类标签。当在足够的数据上进行训练时,ViT表现出卓越的性能,其性能比同类最新的CNN少四倍。为了促进在这一领域的更多研究,我们将代码和模型都开源了。
继续阅读