大数据挖掘—(八):scrapy爬取数据保存到MySql数据库
通过往期的文章分享,我们了解了如何爬取想要的数据到Items中,也了解了如何操作MySQL数据库,那么我们继续完善我们的爬虫代码,把爬取的items,保存到MySQL数据库中。
继续阅读
通过往期的文章分享,我们了解了如何爬取想要的数据到Items中,也了解了如何操作MySQL数据库,那么我们继续完善我们的爬虫代码,把爬取的items,保存到MySQL数据库中。
继续阅读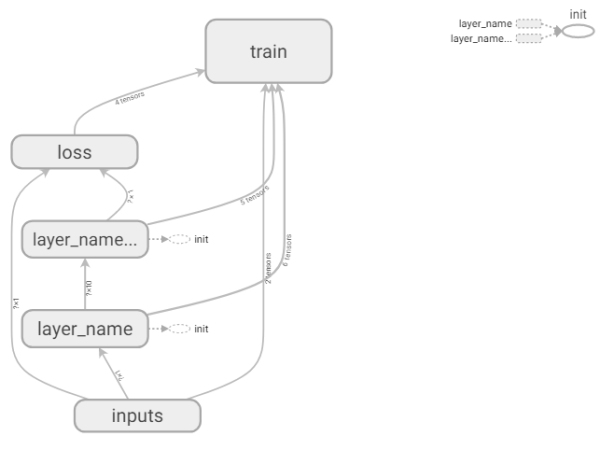
TensorBoard是一个可视化工具,能够有效地展示Tensorflow在运行过程中的计算图、各种指标随着时间的变化趋势以及训练中使用到的数据信息。TensorBoard 和 TensorFLow 程序跑在不同的进程中,TensorBoard 会自动读取最新的 TensorFlow 日志文件,并呈现当前 TensorFLow 程序运行的最新状态。
继续阅读
本期分享一下MySQL数据的基本增减删查的操作
继续阅读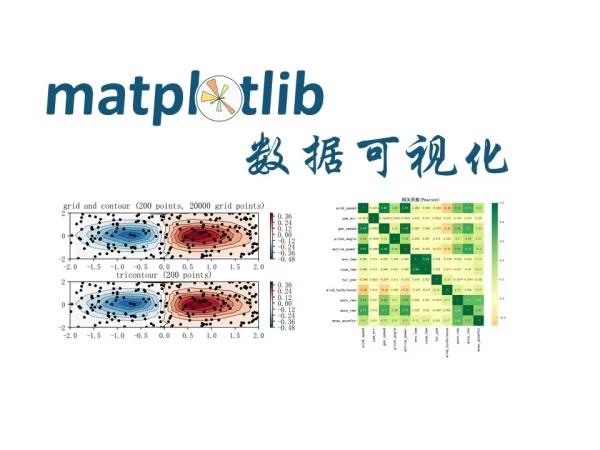
上期分享了matplotlib,那我们利用定义层的代码来实现如何使用matplotlib动态演示训练结果
继续阅读
MySQL 是最流行的关系型数据库管理系统,在WEB应用方面 MySQL 是最好的RDBMS(Relational Database Management System:关系数据库管理系统)应用软件之一,MySQL 是开源的,并且支持多种语言,包括C、C++、Python、Java、Perl、PHP、Eiffel、Ruby和Tcl等。
继续阅读
Matplotlib 是一个 Python 的 2D绘图库,它以各种硬拷贝格式和跨平台的交互式环境生成出版质量级别的图形。
继续阅读
通过查看网页可以发现,单击小说名字后,就进入了小说详细界面,上面有小说的名字,作者,种类等信息,那我们如何爬取这些信息
继续阅读
前几期的文章,我们介绍了激励函数的感念,为何需要激励函数,那么在TensorFlow中如何使用激励函数
继续阅读
本期简单介绍一下scrapy的自带选择器(selectors)
继续阅读
本期主要介绍一下TensorFlow的结构,Tensorflow 是非常重视结构的, 只有建立好了神经网络的结构, 才能放置一些数据, 进而运行这个结构.
继续阅读