MediaPipe Face Detection可运行在移动设备上的亚毫秒级人脸检测
MediaPipe人脸检测是一种超快速的人脸检测解决方案,具有6个界标和多人脸支持。它基于BlazeFace,BlazeFace是为移动GPU推理量身定制的轻巧且性能良好的面部检测器。检测器的超实时性能使其可应用于需要准确地关注面部区域作为其他任务特定模型:
继续阅读
MediaPipe人脸检测是一种超快速的人脸检测解决方案,具有6个界标和多人脸支持。它基于BlazeFace,BlazeFace是为移动GPU推理量身定制的轻巧且性能良好的面部检测器。检测器的超实时性能使其可应用于需要准确地关注面部区域作为其他任务特定模型:
继续阅读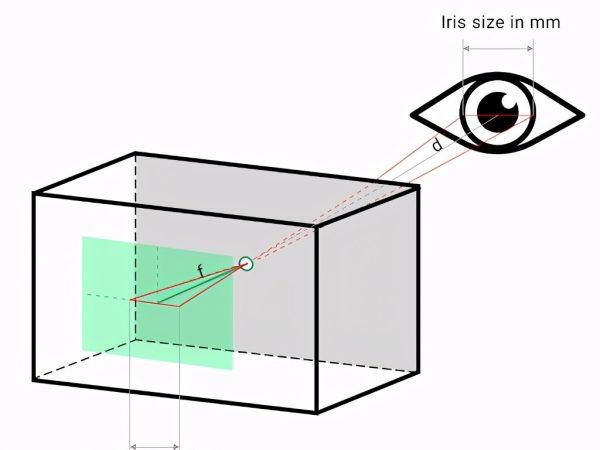
Google发布MediaPipe Iris,这是一种用于精确虹膜估计的新机器学习模型。基于Google在MediaPipe Face Mesh上的工作,该模型能够使用单个RGB摄像机实时跟踪涉及虹膜,瞳孔和眼睛轮廓的界标
继续阅读
Google最近宣布了在Google Meet中模糊和替换背景的方法,该方法使用机器学习(ML)来更好地突出显示参与者,而不管他们周围的环境如何。其他
继续阅读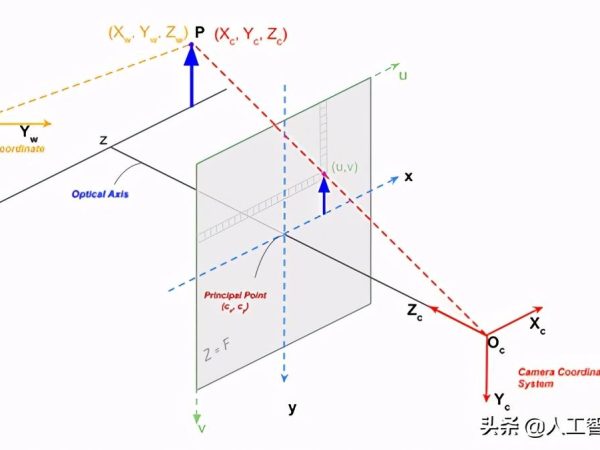
照相机与摄像头,是机器人,人工智能,计算机视觉,工业自动化甚至娱乐行业等多个领域的组成部分。在我们使用此设备时,不仅要了解照相原理外,需要使用特殊的技术对摄像头进行相机校准,特别在自动化驾驶上,需要实时的对照相机进行校准操作
继续阅读
上期文章我们分享了基于OpenCV的超分辨率的代码实现,哪里主要使用到了EDSR、ESPCN、FSRCNN、LapSRN等模型,虽然使用OpenCV能够实现超分辨率,但是图片的清晰图并没有增加,当有一张稍微模糊的图片时,增加分辨率的同时,我们也更希望提高图片的清晰图,如上图的图片,本期文章,我们介绍一下USRNet模型结构
继续阅读
上期视频,我们分享了一个AI来玩贪吃蛇的视频,本期我们讲解一下其基础代码,利用本代码自己也可以写游戏了。
继续阅读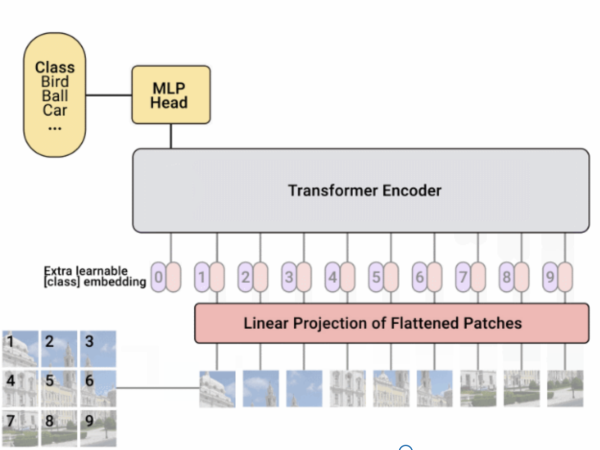
作为朝这个方向迈出的第一步,我们介绍了(ViT),这是一种视觉模型,该模型尽可能地基于最初为基于文本的任务而设计的Transformer体系结构。ViT将输入图像表示为图像块序列,类似于在将”变形金刚”应用于文本时使用的单词嵌入序列,并直接预测图像的类标签。当在足够的数据上进行训练时,ViT表现出卓越的性能,其性能比同类最新的CNN少四倍。为了促进在这一领域的更多研究,我们将代码和模型都开源了。
继续阅读
什么是视频与图片的超分辨率,总结一下便是给一张分辨率比较低的图片,进行超分辨率的处理后,生成比较清晰的高分辨率的图片,上图图片完美解释了超分辨率的过程,由于不同的算法不同,处理的结果也不相同,本期我们介绍一下如何进行图片的超分辨率的处理。
继续阅读
前几期的文章,我们分享了人脸468点检测与人手28点检测的代码实现过程,本期我们进行人体姿态的检测与评估
继续阅读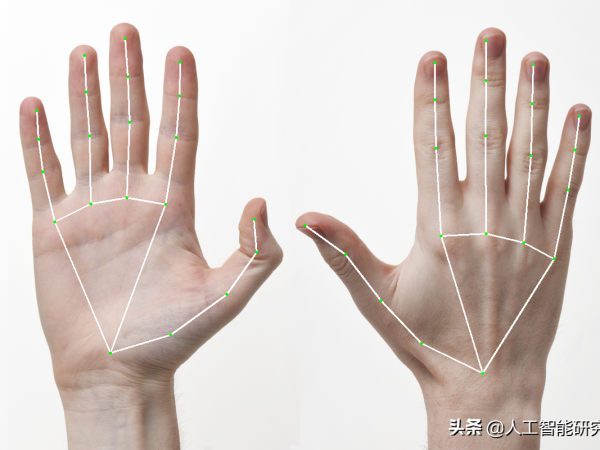
MediaPipe Hands是一种高保真手和手指跟踪解决方案。它采用机器学习(ML)来从一个帧中推断出手的21个3D界标。
继续阅读